|
I am a third-year master's student in the Department of Computer Science at Tsinghua University , advised by Prof. Jun Zhu. In 2022, I obtained my B.S. in the School of Mathematical Sciences at Peking University. My research interests lie in computer vision (e.g., 3D AIGC and video generation), multimodal large models (e.g., native large models), and reinforcement learning from human feedback (DPO, GRPO). My email:yejl23@mails.tsinghua.edu.cn Email / CV / Google Scholar / Github |

|
|
|
|
*equal contribution †Project leader |

|
Junliang Ye*, Ruowen Zhao*, Zhengyi Wang*, et. al Arxiv, 2025 [arXiv] [Code] [Project Page] 
We propose DeepMesh-v2, which generates meshes with intricate details and precise topology, surpassing state-of-the-art methods in both precision and quality. |

|
Chunshi Wang*, Junliang Ye†*, Yunhan Yang*, et. al Arxiv, 2025 [arXiv] [Code] [Project Page] 
We introduce Part-X-MLLM, a native 3D multimodal large language model that unifies diverse 3D tasks by formulating them as programs in a structured, executable grammar. |

|
Junliang Ye*, Shenghao Xie*, Ruowen Zhao, Zhengyi Wang, Hongyu Yan, et. al Arxiv, 2025 [arXiv] [Code] [Project Page] 
we propose Nano3D, a training-free framework for precise and coherent 3D object editing without masks. |
|
|
|
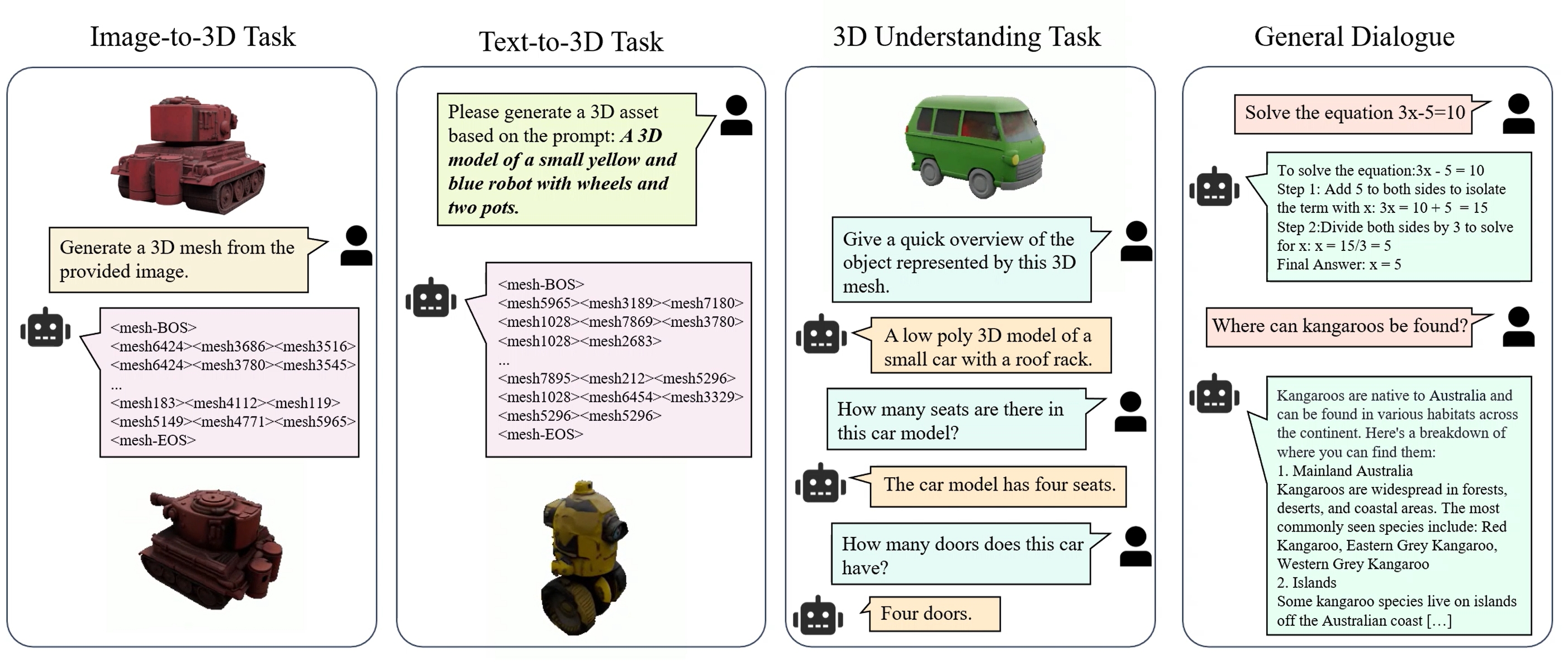
Junliang Ye*, Zhengyi Wang*, Ruowen Zhao*, Shenghao Xie, Jun Zhu NeurIPS, 2025 (Spotlight) [arXiv] [Code] [Project Page] 
We propose ShapeLLM-Omni, a multimodal large model that integrates 3D generation, understanding, and editing capabilities. |

|
Ruowen Zhao*, Junliang Ye*, Zhengyi Wang*, et. al ICCV, 2025 [arXiv] [Code] [Project Page] 
We propose DeepMesh, which generates meshes with intricate details and precise topology, surpassing state-of-the-art methods in both precision and quality. |
|
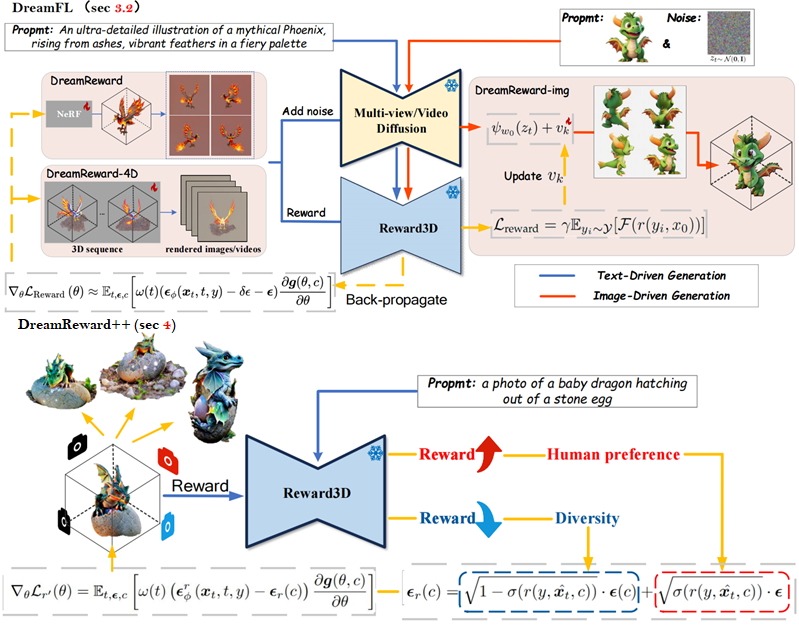
Fangfu Liu, Junliang Ye, et. al TPAMI, 2025 [arXiv] [Code] [Project Page] We present a comprehensive framework, coined DreamReward++, where we introduce a reward-aware noise sampling strategy to unleash text-driven diversity during the generation process while ensuring human preference alignment. Grounded by theoretical proof and extensive experiment comparisons, our method successfully generates high-fidelity and diverse 3D results with significant boosts in prompt alignment with human intention. Our results demonstrate the great potential for learning from human feedback to improve 3D generation. |
|
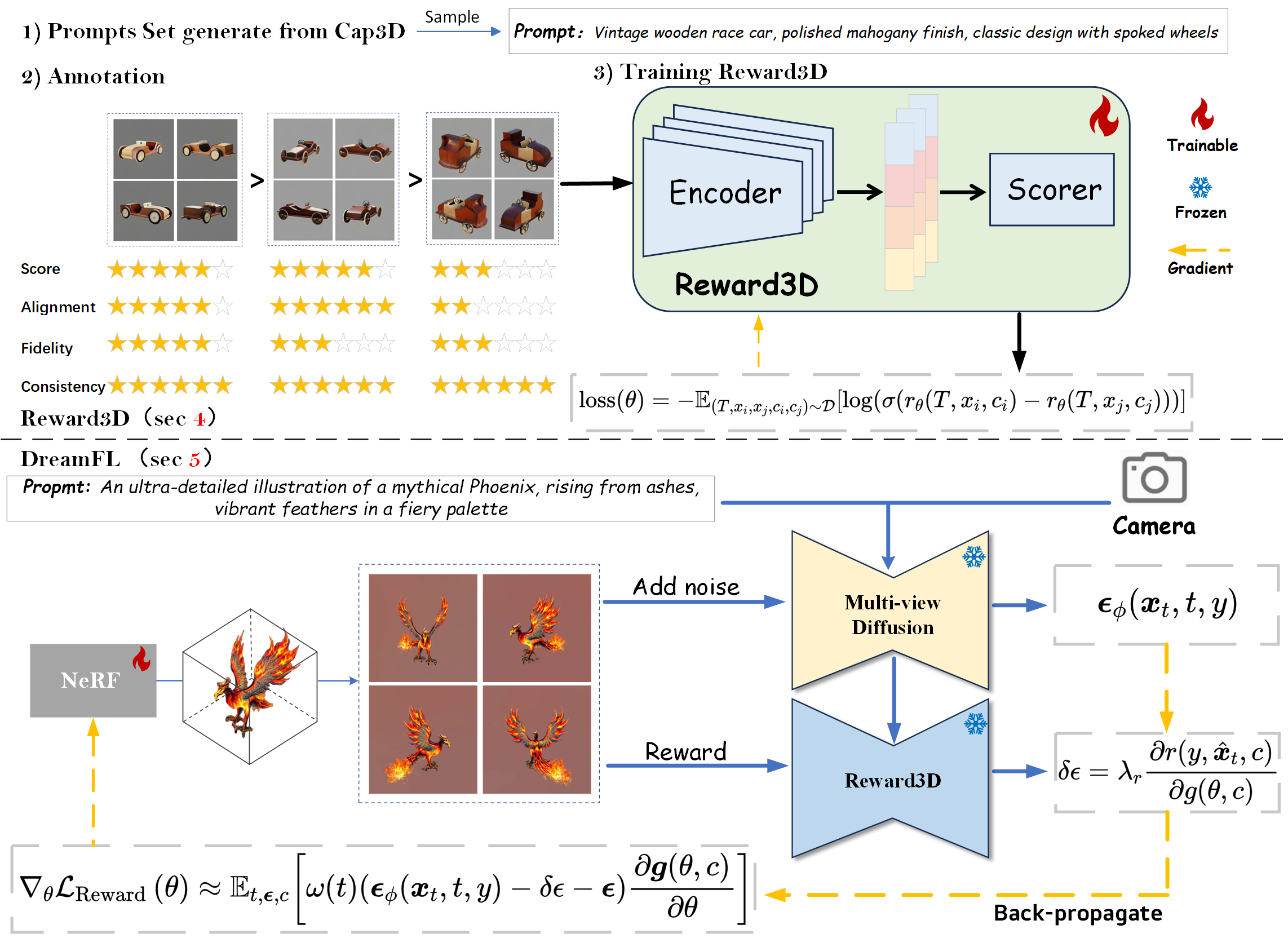
Junliang Ye*, Fangfu Liu*, Qixiu Li, Zhengyi Wang, et. al ECCV, 2024 [arXiv] [Code] [Project Page] 
We present a comprehensive framework, coined DreamReward, to learn and improve text-to-3D models from human preference feedback. |
|
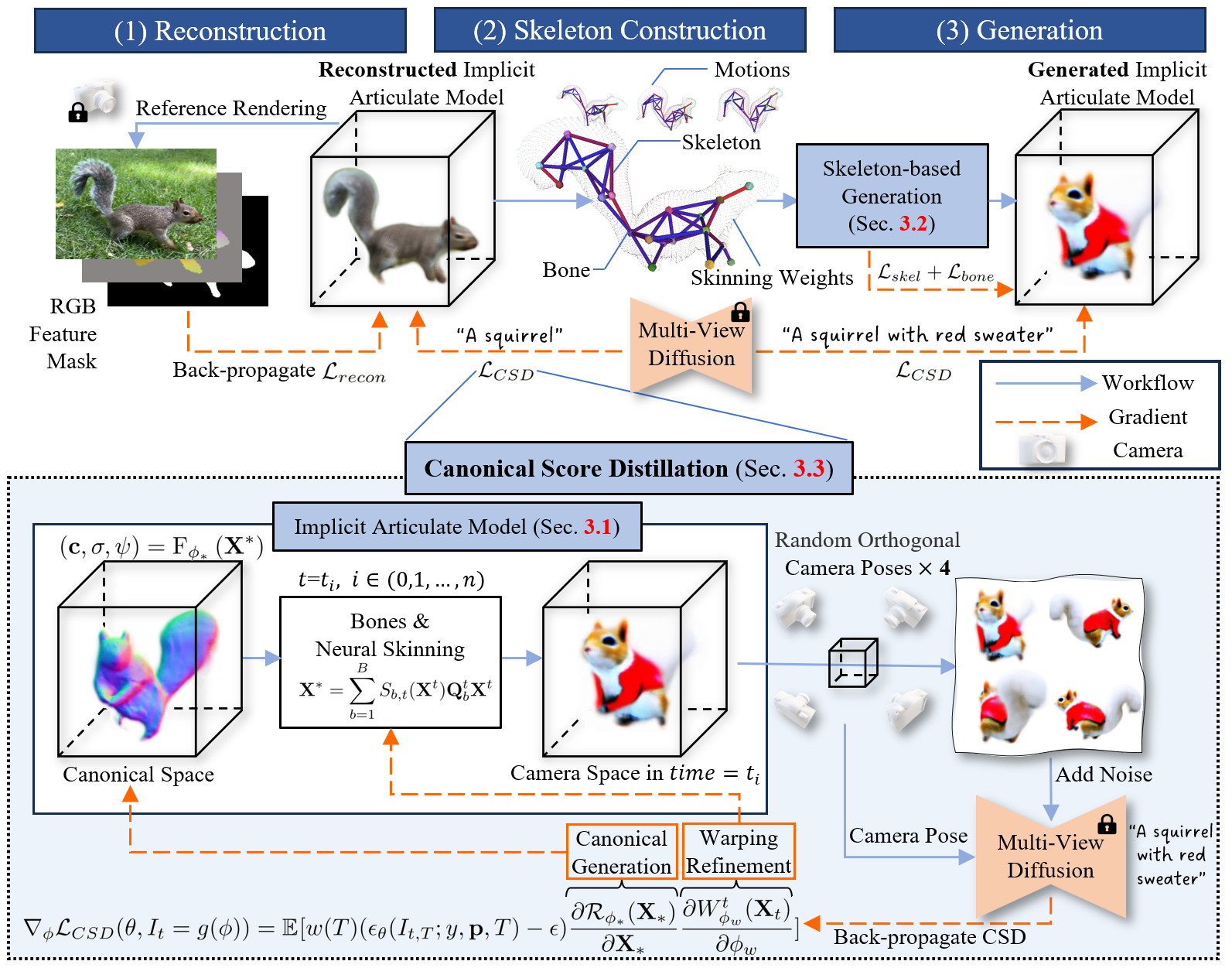
Xinzhou Wang, Yikai Wang, Junliang Ye, et. al ECCV, 2024 [arXiv] [Code] [Project Page] 
We propose ANIMATABLEDREAMER, a framework with the capability to generate generic categories of non-rigid 3D models. |
|
|
|
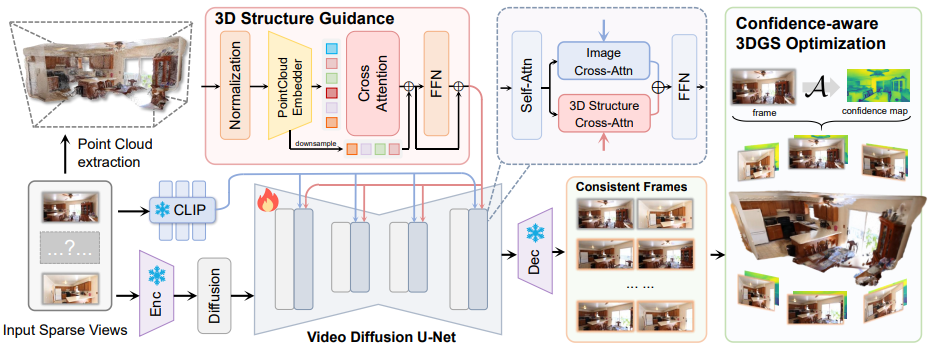
Fangfu Liu*, Wenqiang Sun*, Hanyang Wang*, Yikai Wang, Sun Haowen, Junliang Ye, Jun Zhang, Yueqi Duan Arxiv, 2024 [arXiv] [Code] [Project Page] 
In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. |
|
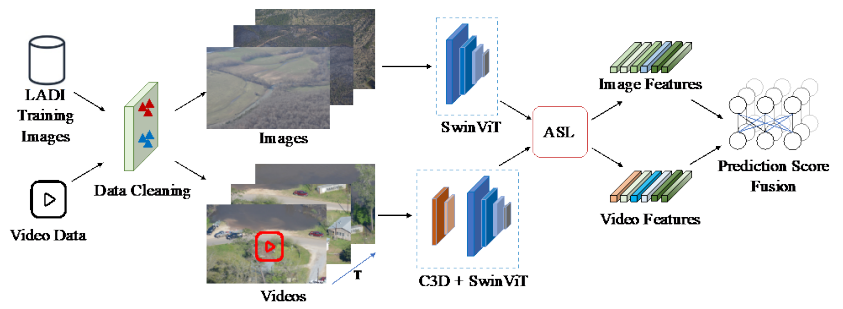
Yanzhe Chen, HsiaoYuan Hsu, Junliang Ye, Zhiwen Yang, Zishuo Wang, Xiangteng He, Yuxin Peng Virtual, Online [arXiv] [Code] [Project Page] We achieved first place in the TRECVID 2022 competition. |
|
|
|
|
© Junliang Ye | Last updated: 29 Sep, 2025